현대 컴퓨팅의 심장: CPU와 GPU 아키텍처의 구조적 이해와 최적화 전략

소프트웨어의 성능을 극한으로 끌어올려야 하는 개발자나 컴퓨터 공학도에게 하드웨어 아키텍처에 대한 이해는 필수적입니다. . 단순히 코드를 작성하는 것을 넘어, 우리가 작성한 명령어가 물리적 장치에서 어떻게 처리되는지 아는 것은 최적화의 출발점이기 때문입니다. . 특히 AI와 빅데이터 처리의 시대가 도래하며 GPU의 중요성은 그 어느 때보다 강조되고 있습니다. .
1. 설계 철학의 차이: CPU vs GPU
CPU와 GPU는 근본적으로 다른 목적을 위해 설계되었습니다. . CPU는 복잡한 제어 로직을 처리하고 순차적인 애플리케이션 실행에 최적화되어 있는 반면, GPU는 수천 개의 연산을 동시에 처리하는 병렬화된 애플리케이션에 특화되어 있습니다. .
- CPU (Central Processing Unit)
- 강력한 ALU: 개별 연산 속도가 매우 빠른 소수의 산술 논리 장치(ALU)를 보유합니다. .
- 대용량 캐시 메모리: ALU당 할당된 캐시 메모리가 커서 데이터 접근 지연(Latency)을 최소화합니다. .
- 복잡한 제어 장치(Control Unit): 분기 예측 및 복잡한 명령어 스케줄링을 담당하는 정교한 컨트롤러를 갖추고 있습니다. .
- GPU (Graphics Processing Unit)
- 수천 개의 ALU: 상대적으로 작고 단순한 수천 개의 ALU(또는 코어)를 통해 방대한 양의 데이터를 동시에 처리합니다. .
- 작은 개별 캐시: 코어당 캐시 용량은 작지만, 전체적인 데이터 처리량(Throughput) 극대화에 집중합니다. .
- 병렬성 중심: 수술실에서 여러 명의 전문의가 유기적으로 협력하듯, 대규모 데이터를 병렬로 처리하는 구조를 지닙니다. .
2. 실행 모델과 종속성: Sequential vs Parallel
코드 실행 방식에서도 두 장치는 큰 차이를 보입니다. . 명령어 간의 종속성(Dependency) 유무는 어떤 프로세서를 선택할지 결정하는 핵심 기준이 됩니다. .
- 종속적 명령어 (Dependent Instructions): 이전 연산 결과가 다음 연산의 입력값이 되는 경우(예:
R1 = R2 + R3후R4 = R1 * R5), 순차 처리에 최적화된 CPU가 유리합니다. . - 독립적 명령어 (Independent Instructions): 각 연산이 서로 영향을 주지 않는 경우(예: 이미지의 각 픽셀 값 변경), 수천 개의 코어가 동시에 계산을 수행하는 GPU가 압도적인 성능을 발휘합니다. .
하드웨어적으로 CPU와 GPU는 PCI Express 버스를 통해 통신하며, 각각 독립적인 메모리 영역(Host Memory vs Device Memory)을 사용합니다. . 효율적인 프로그래밍을 위해서는 CPU 메모리에서 GPU 메모리로 데이터를 복사하는 비용까지 고려해야 합니다. .
3. NVIDIA A100: 현대 AI 아키텍처의 정수
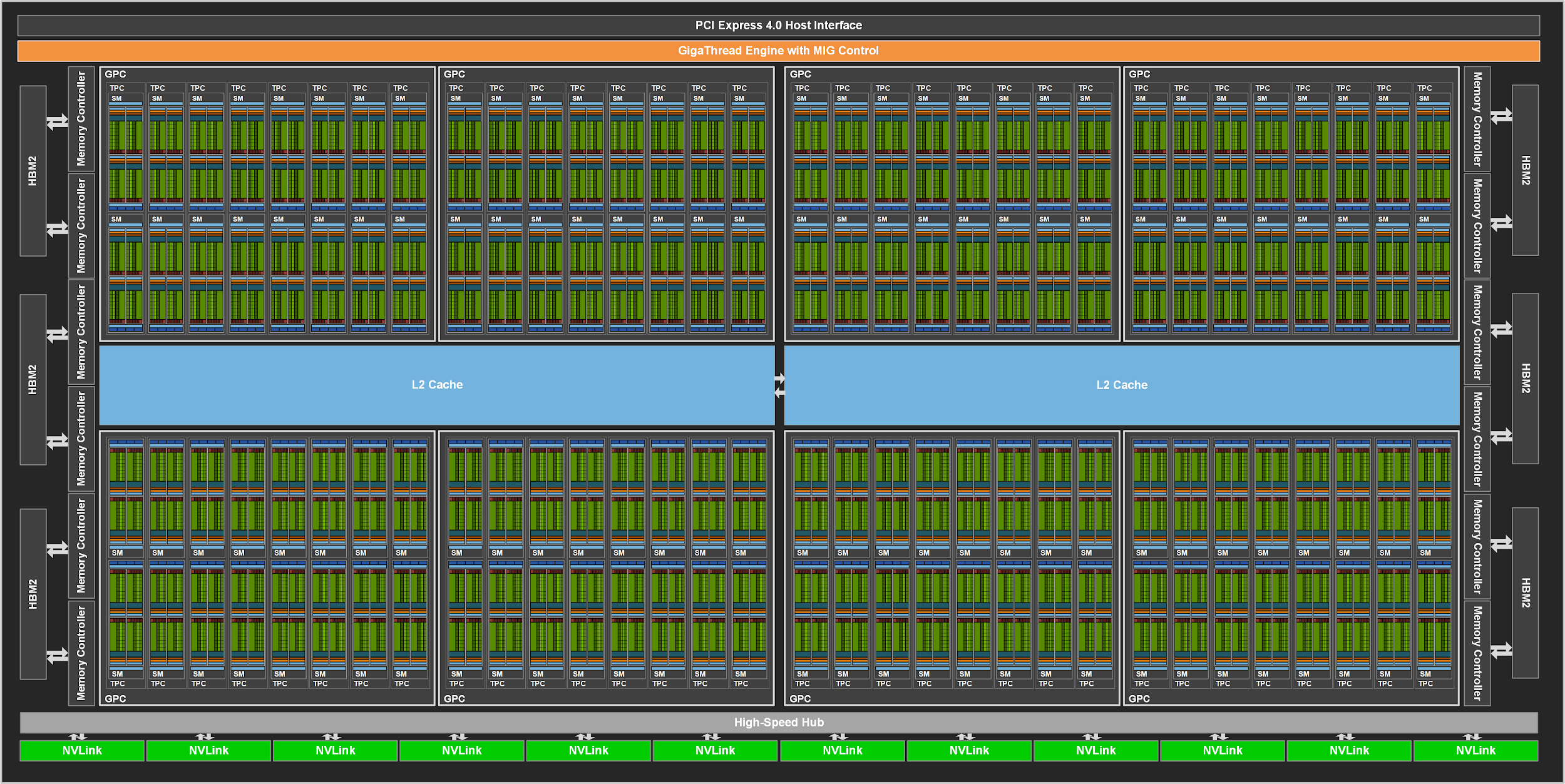
현대 딥러닝 아키텍처의 기준이 되는 NVIDIA A100(Ampere 아키텍처)은 고도의 병렬 처리를 위해 설계된 복합적인 유닛들의 집합체입니다. .
- SM (Streaming Multiprocessor): GPU의 핵심 연산 단위로, A100에는 최대 108개의 SM이 탑재되어 있습니다. .
- CUDA 코어: 단정밀도 부동소수점(FP32) 연산을 수행하는 6,912개의 코어가 장치 전체에 분산되어 강력한 연산력을 제공합니다. .
- Tensor 코어: AI 연산에 특화된 3세대 텐서 코어가 SM당 4개(총 432개) 탑재되어 매트릭스 연산을 가속화합니다. .
- 메모리 아키텍처: 5개의 HBM2 스택과 10개의 512비트 메모리 컨트롤러를 통해 방대한 대역폭을 확보합니다. .
이러한 강력한 하드웨어는 메타(Meta)의 AI 연구용 슈퍼클러스터(RSC)와 같은 거대 컴퓨팅 환경의 기반이 됩니다. . RSC는 총 6,080개의 NVIDIA A100 GPU를 인피니밴드(InfiniBand) 네트워크로 연결하여 전례 없는 성능을 구현합니다. .
4. 결론: 개발자를 위한 제언

GPU 프로그래밍은 단순히 라이브러리를 사용하는 수준을 넘어, 하드웨어의 계층적 구조(Registers → Shared Memory → L2 Cache → Global Memory)를 이해하고 이를 효율적으로 관리하는 과정입니다. . 특히 스케줄러와 디스패처가 어떻게 워프(Warp) 단위로 스레드를 관리하는지 이해한다면, 자원 낭비 없는 최적화된 코드를 작성할 수 있을 것입니다. .
더 나은 성능을 갈망하는 개발자라면, 오늘 다룬 CPU와 GPU의 구조적 차이를 명확히 인지하고 각자의 강점에 맞는 아키텍처를 설계하시기 바랍니다.
References:
- [cite_start]Hamdy Sultan, 강의 자료: CPUs and GPUs [cite: 1-10].
- [cite_start]The CUDA Handbook: A Comprehensive Guide to GPU Programming[cite: 8].
- [cite_start]Meta AI Research: Introducing the AI Research SuperCluster[cite: 10].
- [cite_start]TOP500 슈퍼컴퓨터 리스트 (2023/06)[cite: 10].