CPU와 GPU를 구조부터 이해하면 코드가 달라 보인다

CUDA를 공부하면서 코드 최적화보다 먼저 CPU와 GPU의 구조를 이해해야 한다는 걸 느꼈다. 어떤 연산을 어디에 올려야 하는지, 왜 GPU가 AI 연산에 압도적인지 — 구조를 알면 자연스럽게 이해된다.
설계 철학의 차이: CPU vs GPU
두 장치는 근본적으로 다른 목적을 위해 설계됐다.
CPU (Central Processing Unit)
- 강력한 ALU 소수: 개별 연산 속도가 매우 빠른 산술 논리 장치 몇 개
- 대용량 캐시: ALU당 할당된 캐시가 커서 데이터 접근 지연(Latency)을 줄인다
- 복잡한 제어 장치: 분기 예측, 복잡한 명령어 스케줄링
GPU (Graphics Processing Unit)
- 수천 개의 ALU: 상대적으로 단순하지만 수천 개가 동시에 돌아간다
- 작은 개별 캐시: 코어당 캐시는 작지만 전체 처리량(Throughput)을 극대화한다
- 병렬성 중심: 대규모 데이터를 동시에 처리하는 구조
한 명의 전문가가 순차적으로 처리하는 게 CPU라면, 수천 명의 단순 작업자가 동시에 처리하는 게 GPU다.
어떤 연산에 뭘 써야 하나
명령어 간의 종속성이 핵심 기준이다.
종속적 명령어: 이전 연산 결과가 다음 연산의 입력값이 되는 경우 (R1 = R2 + R3 후 R4 = R1 * R5). 순차 처리가 필요하므로 CPU가 유리하다.
독립적 명령어: 각 연산이 서로 영향을 주지 않는 경우 (이미지 각 픽셀 값 변환 등). GPU가 수천 개 코어로 동시에 처리하면 압도적이다.
하드웨어적으로 CPU와 GPU는 PCI Express 버스로 통신하고, 각각 독립적인 메모리 영역을 쓴다. CPU 메모리에서 GPU 메모리로 데이터를 복사하는 비용도 실제 최적화에서는 고려해야 한다.
NVIDIA A100: AI 연산의 기준점
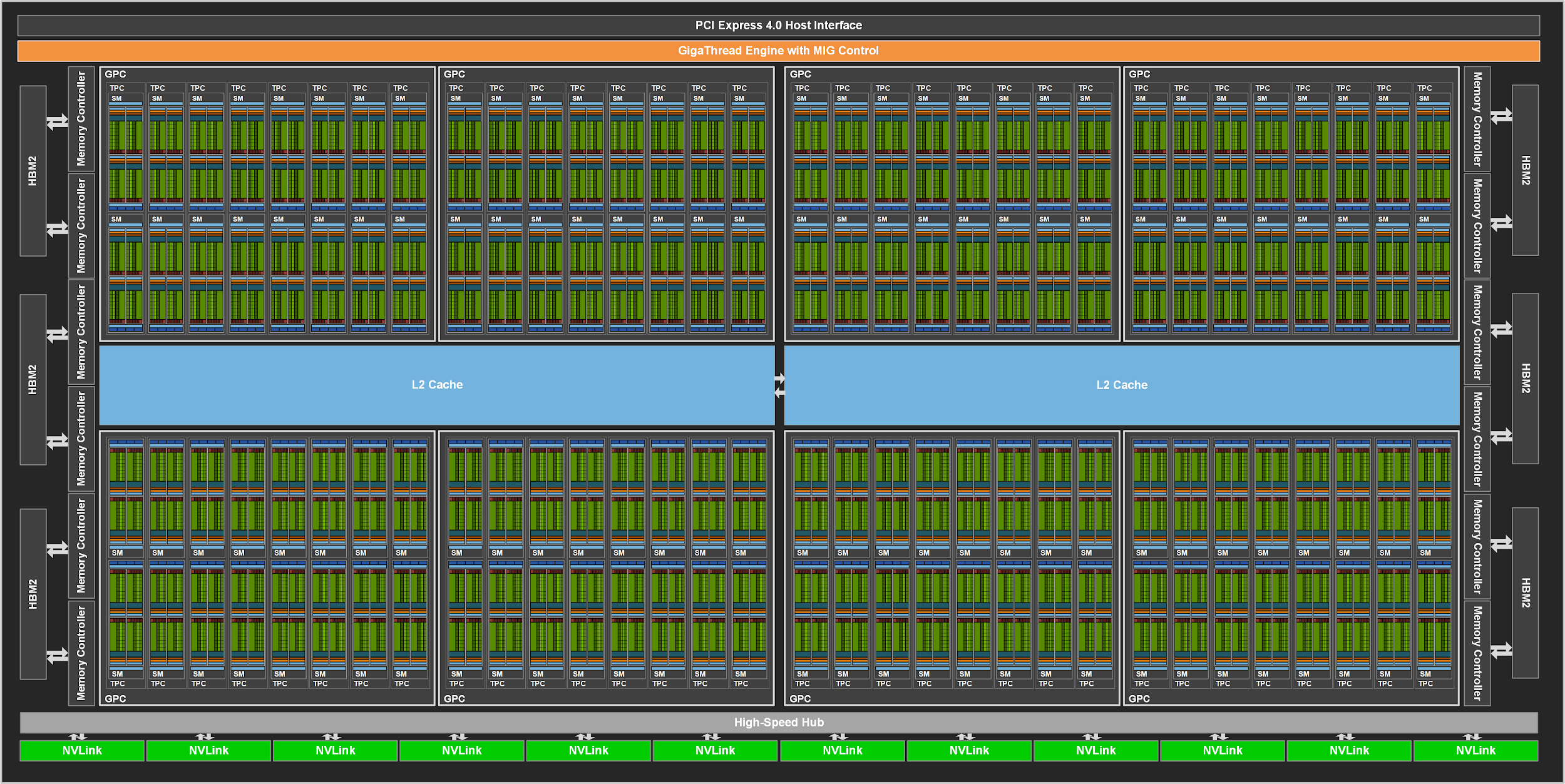
A100(Ampere 아키텍처)이 딥러닝의 기준점이 된 이유가 구조에 있다.
- SM (Streaming Multiprocessor): GPU의 핵심 연산 단위. A100에는 최대 108개 탑재
- CUDA 코어: FP32 연산을 수행하는 6,912개 코어가 전체에 분산
- Tensor 코어: AI 연산 특화 3세대 텐서 코어가 SM당 4개 (총 432개). 행렬 연산을 가속화
- 메모리: 5개 HBM2 스택, 10개 512비트 메모리 컨트롤러로 넓은 대역폭 확보
메타의 AI 슈퍼클러스터(RSC)는 6,080개의 A100을 InfiniBand 네트워크로 연결해서 운영한다.
개발자로서 챙겨야 할 부분
GPU 프로그래밍은 하드웨어의 계층 구조를 이해하고 효율적으로 관리하는 과정이다.
메모리 계층: Registers → Shared Memory → L2 Cache → Global Memory
스케줄러가 워프(Warp) 단위로 스레드를 관리하는 방식을 이해하면, 자원 낭비 없는 최적화 코드를 쓸 수 있다. 단순히 라이브러리 쓰는 수준을 넘어서려면 이 구조 이해가 기반이 된다.
CPU와 GPU의 구조적 차이를 명확히 알면, 같은 문제도 어디에 올릴지 판단이 달라진다.
References:
- Hamdy Sultan, 강의 자료: CPUs and GPUs
- The CUDA Handbook: A Comprehensive Guide to GPU Programming
- Meta AI Research: Introducing the AI Research SuperCluster
- TOP500 슈퍼컴퓨터 리스트 (2023/06)